
고정 헤더 영역
상세 컨텐츠
본문

코딩의 종말? 개발 전문가에게 여전히 중요한 코딩
챗GPT 열풍은 세상이 빠르게 변하고 있음을 실감케 했어요. 생성형 인공지능에 대한 전망과 평가가 조금씩 다르지만 변함이 없는 사실은 챗GPT 는 계속 학습하고 있다는 것! 그리고 우리는 AI 시대를 살게 될 거란 것이죠.
그렇다면 AI 시대에 대체 불가능한 경쟁력을 키우기 위해 어떤 학습을 해야 할까요? AI 전문가인 이경일 솔트룩스 대표는 인간의 영역은 사라지지 않을 거고 더 잘할 수 있는 일, 창의적인 일에 집중하게 될 거라고 말합니다.*
AI는 코딩도 할 수 있어요. 하지만 위 논리면 개발자의 역할이 고도화될 뿐 직업 자체가 사라지는 것은 아닙니다. AI 개발, 시스템 설계, AI가 작성한 코드 개선 등 AI를 이용해 개발하고 작업물을 검수해야 하는 숙련된 개발자는 코딩에 대해 누구보다 더 잘 알고 있어야 함은 물론이고요.
개발 전문가가 되고 싶다면? 크롤링으로 재미있게 기초를 다지자!
이제 막 개발에 입문했다면 코딩과의 첫 만남에 호감을 더하기 위해 크롤링을 추천합니다. 웹상의 원하는 정보만 쏙쏙 골라 엑셀 파일로 깔끔하게 출력하고 BI 툴과 연동해 그래프를 그리는 과정! 코딩이 처음인 이 글을 쓰는 마케터에게도 굉장히 신기한 경험이었어요. 컴퓨터에게 쓴 명령어대로 화면이 움직이고 데이터가 저장되는 과정에서 일종의 희열이 느껴지기도 했죠.
오늘은 예비 개발자 혹은 코딩을 경험하고 싶은 누구라도 마케터와 함께 네이버 쇼핑몰 데이터를 크롤링해 보는 게 어떨까요? 그럼, 지금부터 코딩하는 즐거움에 푹 빠져 봐요!
파이썬 크롤링으로 네이버 스마트 스토어 정보 가져오기
파이썬과 셀레니움
파이썬의 문법은 초심자가 배우기 쉬워요. 게다가 파이썬 자체가 사용 목적이 광범위합니다. 간단한 크롤링에도 쓰이지만 인공 지능을 만드는 데도 쓰이죠. 실제로 파이썬을 사용하는 유저 수도 많아 입문자에게 추천하는 언어입니다.
셀레니움은 파이썬 라이브러리로 크롬 브라우저 웹 페이지에서 마우스 역할을 할 수 있어요. 셀레니움의 도움을 받으면 복사와 붙여넣기를 하며 자료를 만들지 않아도 자동으로 빠르게 데이터를 모을 수 있습니다.
이제 코드를 작성해 봅시다!
필요한 작업 순서
- 웹상 가져올 데이터 구조 및 동작 파악
- 페이지 이동 동작 함수화
- 필요한 데이터 추출 함수화
- 필요한 만큼 반복해 실행
- 추출 데이터 가공
- 태블로를 활용한 시각화
위 작업이 모두 끝나면 Run 버튼을 누르는 동작 하나로 분석하고 싶던 데이터들이 도표로 변하는 마법을 경험할 수 있어요. 오늘 우리가 할 작업은 위 프로세스에서 데이터를 추출부터 엑셀 다운까지입니다.
웹상 가져올 데이터 구조 및 동작 파악 단계는 ‘네이버 쇼핑몰 데이터를 가져오려면, 나는 어떻게 해야 할까?’라고 질문해 보면 쉬워집니다. 아마 저라면 네이버 브라우저 열기->쇼핑 탭 클릭->페이지 끝(또는 원하는 데이터까지) 마우스 스크롤->원하는 데이터 카피의 과정을 거칠 거예요.
또한 크롤링을 위해 데이터의 구조를 알아야 해요. 크롬 브라우저에서 마우스 우클릭 후 검사를 누르면 웹 페이지의 자세한 소스를 볼 수 있고 구조도 파악할 수 있죠.
#네이버 웹페이지 오픈
browser.get('https://www.naver.com')
#쇼핑 탭 클릭
browser.find_element(By.CSS_SELECTOR, "#gnb .list_nav .shop").click()
# 인풋 박스
elem = browser.find_element(By.CSS_SELECTOR, "._searchInput_search_text_3CUDs")
# 에코백 입력
elem.send_keys('에코백')
# 엔터 클릭 --3
elem.send_keys(Keys.ENTER)위 소스는 네이버 브라우저를 열고 쇼핑 검색바에서 에코백을 검색한 결과를 출력합니다.
# 브라우저를 스크롤해서 밑으로 내리는 함수
def scroll_down() :
browser.find_element(By.TAG_NAME, 'body').send_keys(Keys.PAGE_DOWN)한 페이지의 모든 데이터를 가지고 오기 위해 스크롤 함수를 만들어요.
# 이름
def data_name(num) :
try:
name = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[1]/a').text
except:
name = ''
return name각 상품의 이름을 가져오기 위한 소스입니다. 여러 데이터의 상품 이름에 접근하기 위해 XPATH를 이용했어요. 자세히 보면 XPATH의 가운데 변수를 넣어 함수에 들어오는 인자에 따라 값을 증가시키며 순차적으로 html 노드에 접근하게 했습니다.
가격, 리뷰 수, 구매 건수 등 이름 외 가지고 오고 싶은 데이터의 XPATH를 조회한 후 유사하게 함수를 완성하면 70% 정도 작업이 완성돼요!
오늘은 이름, 가격, 리뷰 수, 구매 건수, 찜 수, 상품 링크를 가지고 오도록 하겠습니다. 전체 소스는 맨 하단에 공개합니다.
그럼 계속 코딩해 볼까요?
# 상품을 4개씩 스크롤
for num in range(41) :
if num % 4 == 0:
for x in range(0,4) :
scroll_down()
time.sleep(0.5)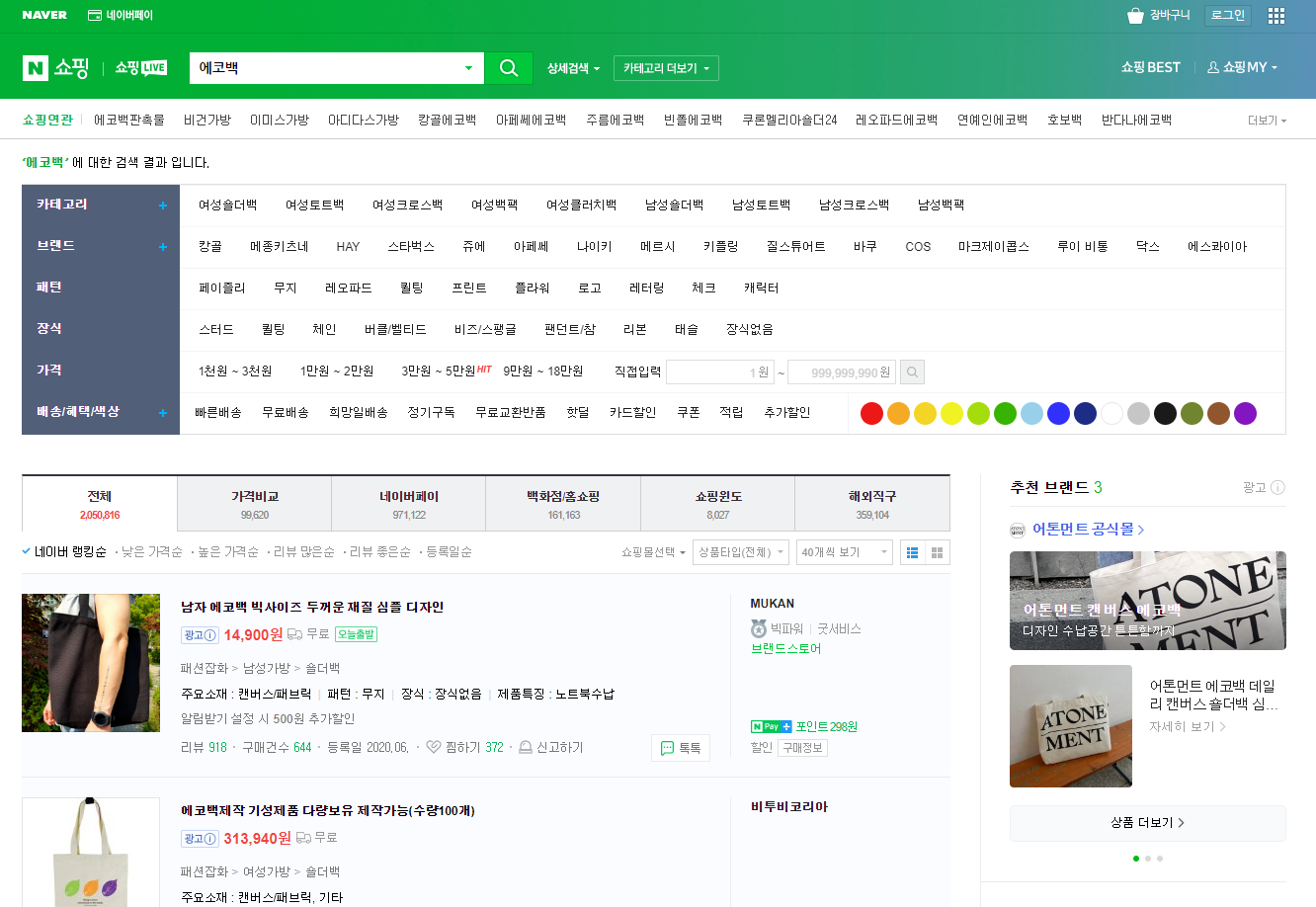
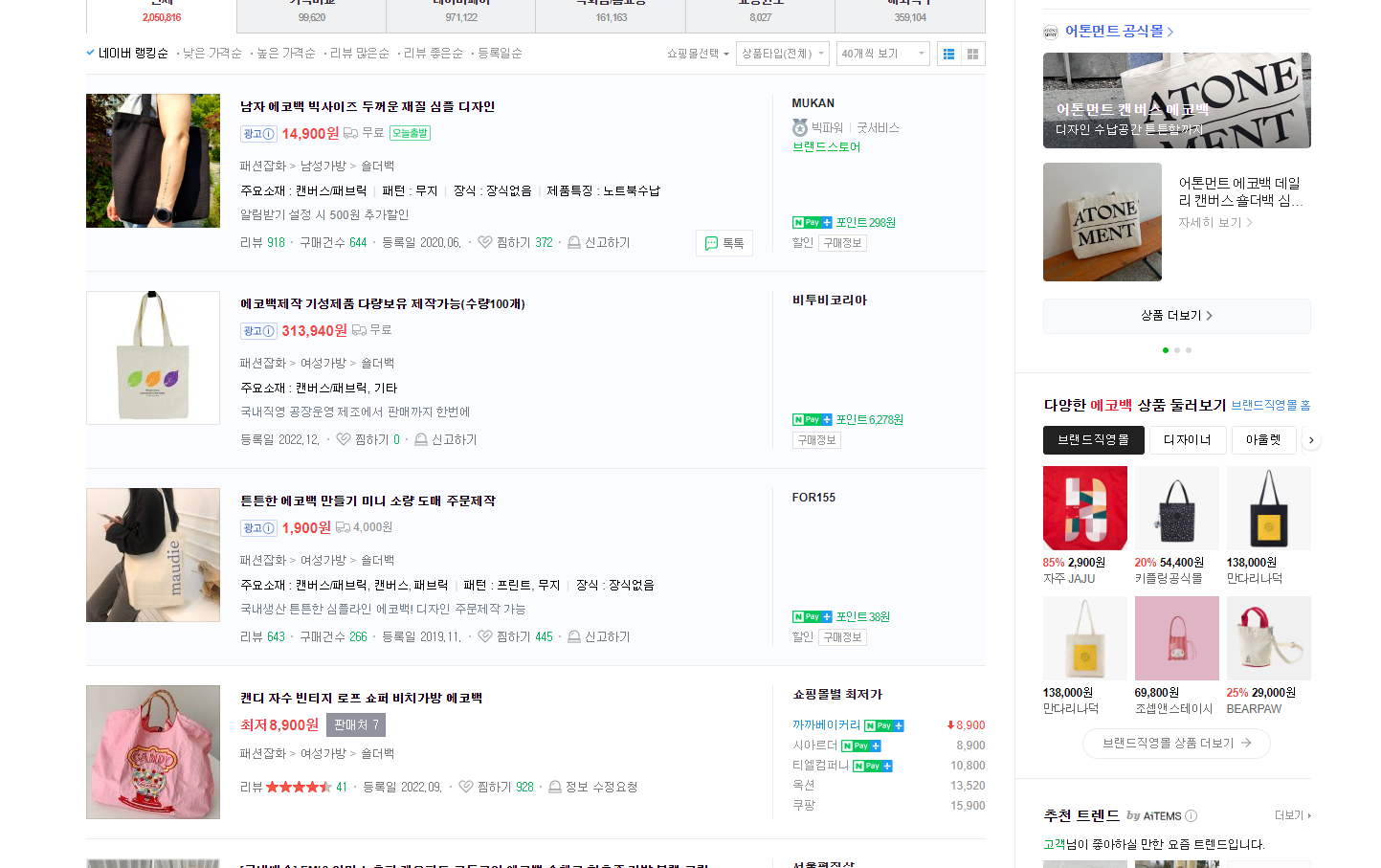
앞서 스크롤 함수를 만들었는데 상품 4개가 들어가면 화면이 꽉 차기 때문에 4개를 조회하고 스크롤 함수를 호출합니다. 에코백을 검색하면 첫 화면에 2개의 상품이 나오지만, 검사를 통해 소스를 보면 첫 화면 로딩 시 5개의 상품을 확인할 수 있고 따라서 소스도 잘 작동하는 걸 알 수 있습니다.
# 엑셀 파일 관련
f = open(r"/Users/yeonuson/PyCharmProjects/pythonProject/data.csv", 'w', encoding='CP949', newline='')
csvWriter = csv.writer(f)
# 제목행
csvWriter.writerow(['상품 명', '가격', '리뷰 수', '구매 수', '찜 수', '상품 링크'])엑셀 파일 관련해 작성해야 하는 소스입니다. 파일을 저장할 위치를 정하고 데이터 입력 전에 제목 행을 추가해서 1행에는 가져올 자료들의 이름을 명시해 줍니다.
# 엑셀에 한 행씩 입력
for x in range(41) :
csvWriter.writerow([data_name(x), data_price(x), data_review(x), data_buynum(x), data_zzimnum(x), data_link(x)])
# 파일 닫기
f.close()엑셀에 한 행씩 상품 정보를 가져오는 함수를 호출해 입력해 주고 파일을 닫아줍니다.
여기까지 코딩한 후 Run 버튼을 누르면 자동으로 크롤링 되고 엑셀 파일이 생성되는 걸 확인할 수 있습니다. 인터넷상에 공개된 모든 정보를 수집이 가능하다는 점에서 활용도가 높고 간단하고 지루하지 않게 코딩을 배우기에도 좋죠.
코딩에 조금이라도 관심이 있다면 엑셀과 같은 프로그램을 이용하기보다 직접 크롤링을 배워보는 걸 적극 추천합니다.
위 내용은 구재홍 저자의 《예제부터 배우는 거꾸로 파이썬》 (부제: 투자 로또 리뷰 등 6가지 유용한 주제로 시작하는 데이터 크롤링)을 참고해 작성했습니다.
재미를 더할 수 있는 로또 지도 만들기부터 소상공인에게 유용한 배달의 민족 리뷰 크롤링까지 흥미진진한 주제의 6가지 파이썬 프로젝트가 수록되어 있습니다. 책의 앞부분에서 파이썬 기초 문법을 자세히 설명해 초심자가 즐겁게 공부하기에 정말 좋은 책입니다.
마케터도 책을 완독한 후, 책의 내용을 응용해 네이버 스마트스토어 데이터를 무리 없이 크롤링할 수 있었어요. 6개의 프로젝트로 파이썬과 크롤링에 충분한 자신감을 얻을 수 있습니다.
▼책 구매하러 가기▼

[전체 소스]
#필요한 파일을 미리 불러옴
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import csv
#크롬 웹드라이버를 로딩
browser = webdriver.Chrome('/Users/yeonuson/Documents/chromedriver_mac_arm64/chromedriver')
#네이버 웹페이지 오픈
browser.get('https://www.naver.com')
#쇼핑 탭 클릭
browser.find_element(By.CSS_SELECTOR, "#gnb .list_nav .shop").click()
# 인풋 박스
elem = browser.find_element(By.CSS_SELECTOR, "._searchInput_search_text_3CUDs")
# 에코백 입력
elem.send_keys('에코백')
# 엔터 클릭
elem.send_keys(Keys.ENTER)
# 브라우저를 스크롤해서 밑으로 내리는 함수
def scroll_down() :
browser.find_element(By.TAG_NAME, 'body').send_keys(Keys.PAGE_DOWN)
# XPATH 설명 --4
# 이름
def data_name(num) :
try:
name = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[1]/a').text
except:
name = ''
return name
# 가격
def data_price(num) :
try:
price = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[2]/strong/span/span[1]/span').text
except:
price= ''
return price
# 리뷰수
def data_review(num) :
try:
review = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) + ']/div/div/div[2]/div[5]/a[1]/em').text
except:
review = ''
return review
# 구매건수
def data_buynum(num) :
try:
buynum = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[5]/a[2]//*/em').text
except:
buynum = ''
return buynum
# 찜수
def data_zzimnum(num) :
try:
zzimnum = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[5]/span[2]//*/em').text
except:
zzimnum = ''
return zzimnum
# 상품링크
def data_link(num) :
try:
link = browser.find_element(By.XPATH, '//*[@id="content"]/div[1]/div[2]/div/div['
+ str(num) +']/div/div/div[2]/div[1]/a').get_attribute('href')
except:
link = ''
return link
# 엑셀 파일 관련
f = open(r"/Users/yeonuson/PyCharmProjects/pythonProject/data.csv", 'w', encoding='CP949', newline='')
csvWriter = csv.writer(f)
# 제목행
csvWriter.writerow(['상품명', '가격', '리뷰수', '구매수', '찜수', '상품링크'])
# 상품을 4개씩 스크롤
for num in range(41) :
if num % 4 == 0:
for x in range(0,4) :
scroll_down()
time.sleep(0.5)
# 엑셀에 한 행씩 입력
for x in range(41) :
csvWriter.writerow([data_name(x), data_price(x), data_review(x), data_buynum(x), data_zzimnum(x), data_link(x)])
# 파일 닫기
f.close()'책 속으로' 카테고리의 다른 글


댓글 영역